





THE PROBLEM
At the moment in order to put data from various sources into the data archive a multitude of different loading programs are used (SSIS, command-line applications, scripts, etc) each of which uses it's own rules to determine where the source data ends up (largely dependent on what rules the developer used when putting it together) and inter-dependencies are largely invisible.
New feeds are added at a rate of one every other month and the system should cope with this wile keeping track of the dependencies in the database.
DESIGNING THE SOLUTION
In essence the problem this solution is trying to solve is to provide a single point of entry into the data archive where you can put your source data and which will then be put into the archive using a pre-specified set of rules to determine where the data ends up and what format it's in.
A simple diagram for the system is;
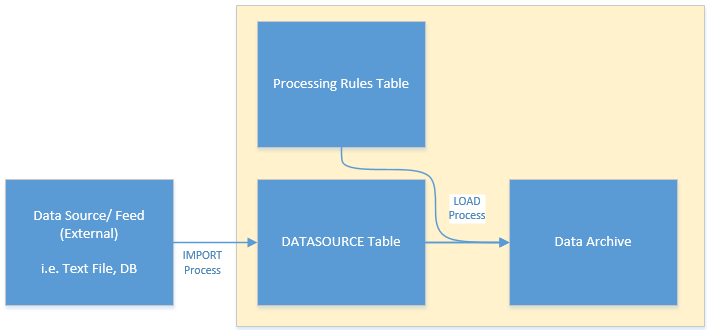 |
| System Diagram |
The aim of the solution will be to process the data as it arrives but it's possible that it could be adapted to work with data in batches.
THE PROPOSAL
I've created a fairly simple structure using the tables;
- SOURCEDATATYPE - This holds a unique reference and description for each different data source
- STAGINGOUTPUT - This table holds the raw data as loaded into the database from the external feed (I went with this name in case it's necessary to use staging tables for the IMPORT process to manipulate the data prior to it being loaded via the LOAD process)
- ENTITY - This is the name for a table that is being created as part of the LOAD process in the Data Archive.
- ENTITYDETAIL - This table contains information on how the data from the source table should be manipulated before being moved into the ENTITY table.
 |
| Database Structure |
Once you've configured the data source type, and entity details then you're ready to start loading data.
In order to load the database I've created a package called DW_LOADDATA. This has two routines;
- ProcessAll, and
- ProcessRow (p_rowID ROWID)
The process row routine performs the following steps;
- Get the new record from STAGINGOUTPUT
- Identify the ENTITY/ENTITYDETAIL for the feed specified in the STAGINGOUTPUT record
- Check to see if the ENTITY exists - if not create it.
- Work out the column name, and if that doesn't exist as part of the ENTITY create it
- Does a value already exist? If so update it (using MERGE), otherwise INSERT the new value
- Mark the STAGINGOUTPUT record as processed
The key is the information in the ENTITY/ENTITYDETAIL tables. For example let's suppose I'm loading sales data and I want to create an ENTITY called SUPPLIER_SALES_BY_MONTH with separate columns for each month of data.
In the ENTITY table I'd create a simple record with the name of the new ENTITY (bearing in mind the actual name of the table will be prefixed with the Short_Code from the SOURCEDATATYPE table) and then in the ENTITYDETAIL table create the following rows;
INSERT INTO ENTITYDETAIL
SELECT 1, 1, 2,
'''PERIOD_'' || TO_CHAR(SO.DATE01, ''YYYYMM'')', -- column_name_expression
'SO.NUMBER01', -- row_unique_expression
'OLD.VALUE = NVL(OLD.VALUE, 0) + SO.NUMBER04', -- value_expression
'NUMBER', -- on_create_type
'0' -- on_create_default
FROM DUAL
UNION SELECT 1, 1, 1,
'''SUPPLIER_NAME''', -- column_name_expression
'SO.NUMBER01', -- row_unique_expression
'OLD.VALUE = SO.TEXT01', -- value_expression
'VARCHAR2(80)', -- on_create_type
'0' -- on_create_default
FROM DUAL
I know "INSERT INTO ..." probably isn't the best way to do this but this is only an example!
As you can see the column_name_expression is looking at the SO (STAGINGOUTPUT) table and formatting the first date to YYYYMM - so a value of 13-JAN-2013 will create/ update the column PERIOD_201301.
The value (for the supplier) is being updated to add on the sales for that month.
The second column that's created is the SUPPLIER_NAME - this is simply the name of the supplier. If I run this using some random test data I end up with a table that looks like;
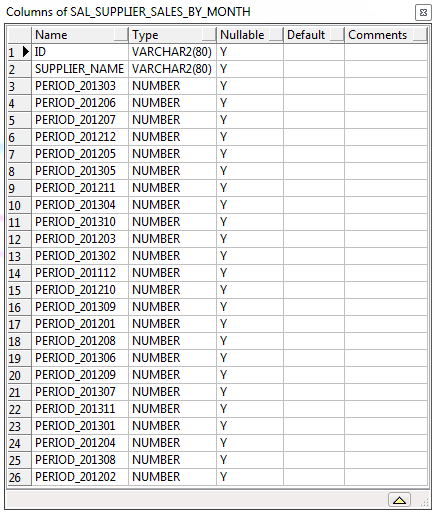 |
| Generated Table |
Let me know in the comments if you find this useful




0 comments:
Post a Comment