This series of posts is going to be a slight departure from normal in that it won't be showing you any code. We are going through the process of designing a CMDB (that's a Configuration Management Database) to hold details for all the systems (500+) that we administer. The point of this post is to, by means of an example, show you the sort of questions you should be asking yourself when you put together a CMDB.
So let's start with a description of a system;
"System X is a fairly simple VB.NET solution deployed using IIS and installed on the server WIN005. It consists of two applications; User Interface (an application open to all users), and Admin Interface (only available to a few).
The Admin Interface works on a vanilla IIS install but the User Interface requires the installation of the Visual Studio 2010 Tools for Office Runtime.
The installation files for the software are located on WIN080\Software (a file share) as are the bi-monthly patch files that are applied.
At the back end the database, SYSXDB, is SQL Server 2008R2 and is held on a SQL Server cluster called SQLC001.
The application uses Active Directory for authentication, and the User Interface renders some information from Google Maps to which it requires access.
The users of the Solution are spread across two Countries; France and the United Kingdom. We have internally configured the system so that in the UK users know the solution as as 'InfoMaps' and in France it's known as 'LocalMaps'."
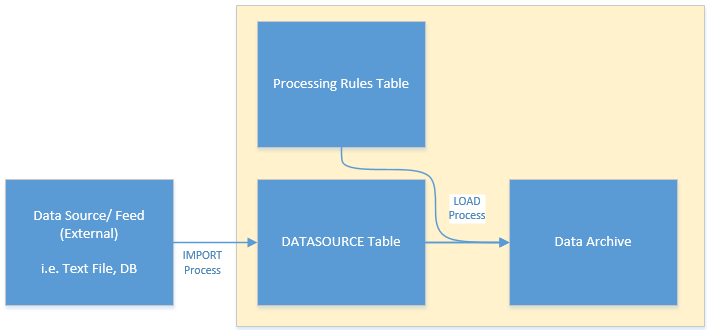
I'm sure there are probably parts in that description that you'll recognise from systems you've worked on. As you can see despite it being only a fairly simple VB.Net website with a couple of plugins there is already quite a lot of information here to capture in our CMDB. If we take this structure and put it into Visio then as a system overview we get something like this;
Now for most small organisations this is probably 95% of the information they're ever going to need. If you're a small company and aren't expecting do significantly increase in size and you're not planning on managing hundreds of systems across the globe then you can make do - let's be honest we all have our "go to guy" for a particular system and so long as they're not on holiday (or haven't left!) then they can keep the system ticking over quite happily from both the users and managements perspecitive.
The problem comes when you don't just have one system, or a few, you start to have tens of systems like this and each system takes some time to administer. Suddenly your team of 3/4 software engineers don't really have any time to do anything new because they're too busy keeping the systems that the business is already relying on working to put in anything new.
Once you approach this level you need to significantly increase the quality of information you are holding on each system; you stop needing "Bob" to fix your problem but instead you need "someone who knows IIS" or "someone who can fix SQL Server". If all the knowledge is in Bob's head then Bob quickly becomes a bottle-neck through which all issues have to go through - this isn't good for Bob (although he might think in the short term that it is!) and it's certainly not good for the company or the users.
So let's go back to the description for System X and look for all the items in the configuration that we might want to store information on in our CMDB. Each of these items will become a Configuration Items (CI) in the CMDB. It's fairly easy looking at the system description to just pick things out;
The sort of questions that need to be picked out from the system description are; have both applications been installed into the same Application Pool in IIS? Is the Application Pool running as a local user or is it using network credentials? How are we connecting to the database? Are users typing in http://win005 to access the site or have we setup DNS entries (http://infomaps for example)? How are we deciding if a user has access to the Admin Interface? Etc.
So let's assume someone technical has gone through the system, had the discussions with the vendor, and found out how everything is not just connected but configured. Here's the list of things we might like to consider turning into CI's in additional the ones we've already identified;
But how do we know we've captured everything? or even captured enough details for us to be able to properly support the system after we've put it in?
In Part 2 we'll look at "testing" our configuration to try and identify the gaps.
So let's start with a description of a system;
"System X is a fairly simple VB.NET solution deployed using IIS and installed on the server WIN005. It consists of two applications; User Interface (an application open to all users), and Admin Interface (only available to a few).
The Admin Interface works on a vanilla IIS install but the User Interface requires the installation of the Visual Studio 2010 Tools for Office Runtime.
The installation files for the software are located on WIN080\Software (a file share) as are the bi-monthly patch files that are applied.
At the back end the database, SYSXDB, is SQL Server 2008R2 and is held on a SQL Server cluster called SQLC001.
The application uses Active Directory for authentication, and the User Interface renders some information from Google Maps to which it requires access.
The users of the Solution are spread across two Countries; France and the United Kingdom. We have internally configured the system so that in the UK users know the solution as as 'InfoMaps' and in France it's known as 'LocalMaps'."
I'm sure there are probably parts in that description that you'll recognise from systems you've worked on. As you can see despite it being only a fairly simple VB.Net website with a couple of plugins there is already quite a lot of information here to capture in our CMDB. If we take this structure and put it into Visio then as a system overview we get something like this;
 |
| System X: An Overview |
The problem comes when you don't just have one system, or a few, you start to have tens of systems like this and each system takes some time to administer. Suddenly your team of 3/4 software engineers don't really have any time to do anything new because they're too busy keeping the systems that the business is already relying on working to put in anything new.
Once you approach this level you need to significantly increase the quality of information you are holding on each system; you stop needing "Bob" to fix your problem but instead you need "someone who knows IIS" or "someone who can fix SQL Server". If all the knowledge is in Bob's head then Bob quickly becomes a bottle-neck through which all issues have to go through - this isn't good for Bob (although he might think in the short term that it is!) and it's certainly not good for the company or the users.
So let's go back to the description for System X and look for all the items in the configuration that we might want to store information on in our CMDB. Each of these items will become a Configuration Items (CI) in the CMDB. It's fairly easy looking at the system description to just pick things out;
- IIS
- WIN005
- User Interface
- Admin Interface
- Visual Studio 2010 Tools for Office Runtime
- WIN080\Software
- SYSXDB
- SQLC001
- Active Directory
- maps.google.com
The sort of questions that need to be picked out from the system description are; have both applications been installed into the same Application Pool in IIS? Is the Application Pool running as a local user or is it using network credentials? How are we connecting to the database? Are users typing in http://win005 to access the site or have we setup DNS entries (http://infomaps for example)? How are we deciding if a user has access to the Admin Interface? Etc.
So let's assume someone technical has gone through the system, had the discussions with the vendor, and found out how everything is not just connected but configured. Here's the list of things we might like to consider turning into CI's in additional the ones we've already identified;
- Application Pool: SystemXUserInterface (Installed on WIN005)
- Application Pool: SystemXAdminInterface (Installed on WIN005)
- SYSTEMXSERVER (Active Directory account Used by both Application Pools and SQLC001 to grant access to SYSXDB)
- "UK InfoMaps Standard Users" (Active Directory Group, Used By "System X User Interface")
- "FR LocalMaps Standard Users " (Active Directory Group, Used by "System X User Interface")
- "UK InfoMaps Administrators" (Active Directory Group, Used By "System X User Interface")
- "FR LocalMaps Administrators" (Active Directory Group, Used by "System X User Interface")
- DNS Entry: LocalMaps.ourcompany.org (Maps to WIN005)
- DNS Entry: InfoMaps.ourcompany.org (Maps to WIN005)
- SMTP.ourcompany.org (Used by System X Admin Interface to send email notifications)
- Firewall Ports: 80,443 (Required for access to WIN005)
- VT001 (Hyper-V server hosting WIN005 - a virtual server)
But how do we know we've captured everything? or even captured enough details for us to be able to properly support the system after we've put it in?
In Part 2 we'll look at "testing" our configuration to try and identify the gaps.